开云体育 12篇效率入选CVPR 2026! 百度杀青视觉与多模态技能多点突破


近日,计较机视觉领域顶级海外会议 CVPR 2026 公布论文委派收尾。百度共12篇辩论效率奏效入选,关联论文掩盖多模态领会与生成、东说念主脸活体识别、矢量舆图、及时新视角合成、自动驾驶3D 场景重建与生成、3D+视频生成等多个前沿辩论办法,体现了百度在视觉与多模态领域的持续技能积聚与蜕变探索。
算作寰球计较机视觉领域最具影响力的学术会议之一,CVPR 与 ICCV、ECCV 比肩为视觉办法三大海外顶级会议。会议长期保持极高的学术圭臬与竞争强度,每年勾引来自寰球顶尖高校与科技公司的宽绰投稿。
频年来,CVPR 论文投稿量持续攀升。根据会议官方邮件奉告,2026 年共有16,092篇论文参加审稿过程,范例委员会最终推节委派4,090篇论文,合座委派率为25.42%。CVPR 2026 将于6月3日至7日在好意思国丹佛举行。
以下为百度入选论文共享:
01.
PP-OCRv5: A Specialized 5M-Parameter Model Rivaling Billion-Parameter Vision-Language Models on OCR Tasks
技俩结合:https://github.com/PaddlePaddle/PaddleOCR
论文简介:PP-OCRv5是一款仅5M 参数的超轻量级 OCR 系统,其中枢亮点在于冲突了“模子越大越好”的传统不雅念戒指,通过数据为中心(Data-Centric)的系统化优化计谋,在 OCR 性能上比好意思以致独特 GPT-4o 等千亿参数的视觉讲话大模子(VLMs)。
技能蜕变: 论文开创了一套针对 OCR 数据的量化分析框架,从难度、准确性、各类性三个维度重构数据计谋。要害发现包括:1)模子检讨存在“难度甜点区”(中等难度数据最高效);2)模子对极少标签噪声具备一定的鲁棒性,从而为智能数据标注提供可能性;3)特征各类性是擢升泛化智商的决定性身分。
应用价值: 算作工业级两阶段(检测+识别)贬责决策,PP-OCRv5不仅贬责了大模子产生幻觉、定位不准及算力腾贵的痛点,更在手写、多讲话及当然场景下弘扬优厚。同期该论文更向业界输出了一套通用的数据处理范式。有劲阐明了通过详尽化的“数据工程”,小模子不错在 OCR 场景比好意思大模子,这一顺次论为 OCR 场景开发高遵循、低老本的群众模子提供了具有实战价值的参考旅途。
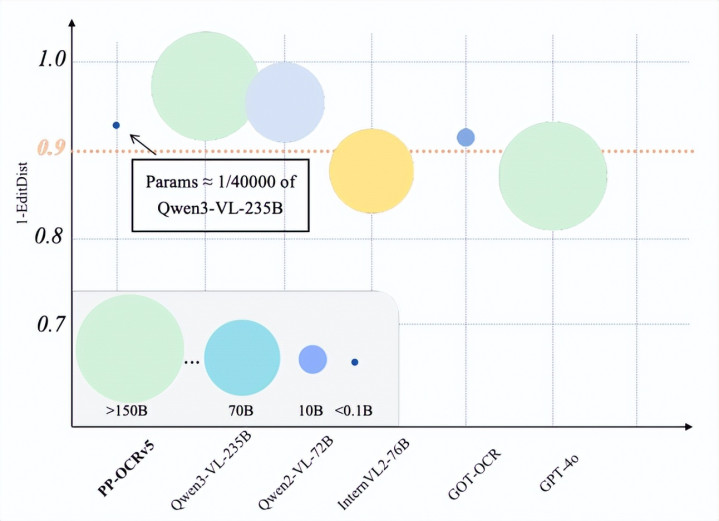
直不雅展示了 PP-OCRv5的极致性价比。在 OCR 任务中,PP-OCRv5以仅5M 的参数目(约为 Qwen3-VL-235B 的四万分之一),杀青了与 GPT-4o、Qwen2-VL 等千亿级大模子相配的准确率(1-EditDist约为0.93),有劲阐明了 PP-OCRv5专用小模子在 OCR 任务上的弘大后劲。
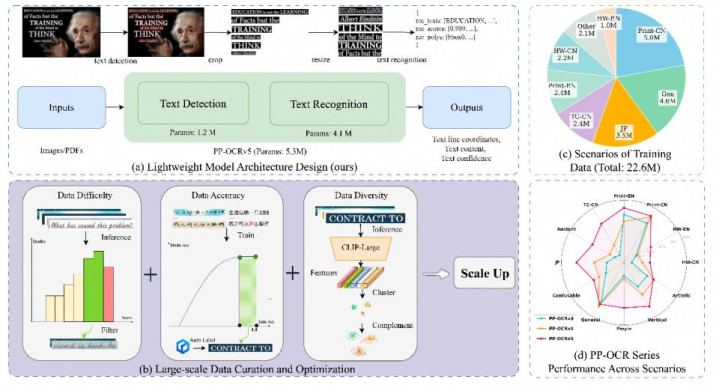
展示了 PP-OCRv5模子架构与数据运转优化过程全景图,该图了了地拆解了 PP-OCRv5“以数据运转小模子”的技能道路。
经典的轻量化两阶段架构(检测1.2M+识别4.1M),确保推理速率;
数据清洗与优化活水线:通过置信度筛选(Data Difficulty)、噪声容忍实验(Data Accuracy)和 CLIP 特征聚类(Data Diversity)三大引擎,构建高质料检讨集;
基于上述计谋构建的2260万样本大领域多场景数据集散播;
最终效率:PP-OCRv5在手写、多讲话、复杂配景等多场景下弘扬优异。
02.
PaddleOCR-VL: Boosting Document Parsing Efficiency and Performance with Coarse-to-Fine Visual Processing
技俩结合:https://github.com/PaddlePaddle/PaddleOCR
论文简介:文档剖判是一项细粒度的任务,图像分辨率对剖判性能有着至关热切的影响。固然当今欺骗视觉讲话模子(VLM)的前沿辩论通过高分辨率输入擢升了模子弘扬,但这经常会导致视觉 Token 数目呈二次方增长,从而权贵加多了计较老本。
咱们将这种低效归因于文档图像中存在宽绰的视觉区域冗余(如空缺配景)。为了贬责这一问题,咱们提议了 PaddleOCR-VL,这是一种新颖的“由粗到精(Coarse-to-Fine)”架构,它专注于语义关联的要害区域,同期禁绝冗余信息,从而同步擢升剖判效率与性能。具体而言,咱们提议了一个轻量级的有用区域聚焦模块(VRFM),该模块欺骗定位与陡立文联系瞻望智商来识别有用的视觉 Token。随后,咱们瞎想并检讨了一个紧凑且遒劲的0.9B 视觉讲话模子(PaddleOCR-VL-0.9B),在 VRFM 输出的指点下进行细粒度识别,幸免了对整幅大图的告成计较。
平时的实验标明,PaddleOCR-VL 在页面级剖判和元素级识别方面均达到了开始进(SOTA)的水平。它不仅权贵优于现存贬责决策,与顶级 VLM 比拟也极具竞争力,况且在大幅减少视觉 Token 数目和参数目的同期,杀青了极快的推理速率。这充分阐明了针对性的“由粗到精”剖判决策在杀青准确、高效文档领会方面的超卓有用性。
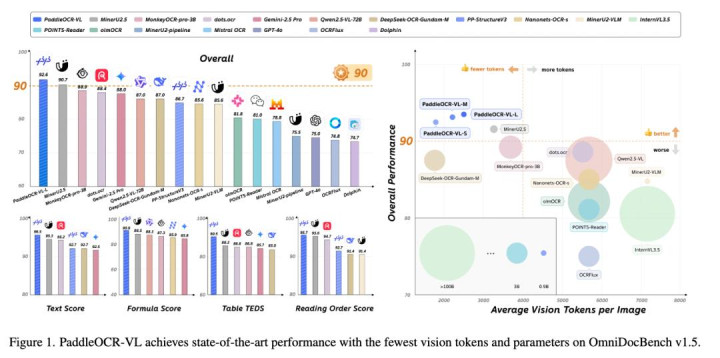
(左侧)在 OmniDocBench v1.5泰斗榜单上,PaddleOCR-VL 在轮廓得分和子项狡计上均独特了 MinerU2.5、GPT-4o、Qwen2.5-VL-72B 等国表里顶尖模子。
(右侧)PaddleOCR-VL 的三个版块(S, M, L)一王人位于图表的最左上角(“黄金区域”)。这意味着它以极少的视觉 Token(经常只须竞品的1/3到1/2)和更小的模子参数,杀青了比72B 等其他大模子更高的文档剖判精度。
03.
FaithFusion: Harmonizing Reconstruction and Generation via Pixel-wise Information Gain
论文结合:https://arxiv.org/abs/2511.21113
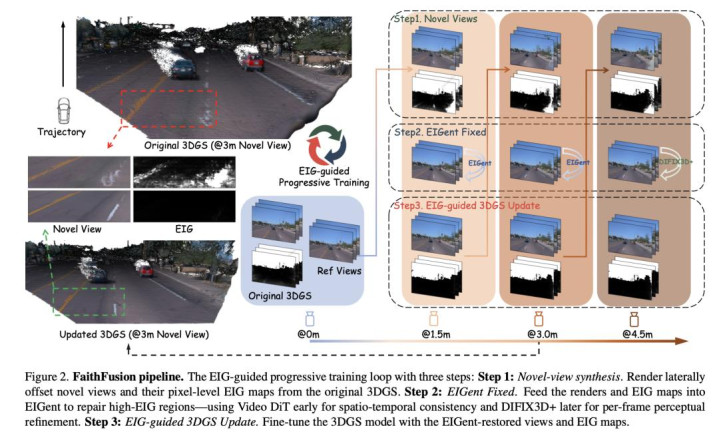
论文简介:在可控的驾驶场景重建和3D 场景生成中,在弘大的视角变化下保持几何保真度,同期合成视觉上合理的(传神的)外不雅是至关热切的。但是,将基于几何的3DGS(3D 高斯溅射)与外不雅运转的扩散模子(Diffusion models)进行有用交融濒临着固有的挑战,因为短缺像素级的、3D 一致性的剪辑圭臬,这经常会导致过度树立(over-restoration)和几何漂移(geometric drift)。
为了贬责这些问题,咱们引入了 FaithFusion,这是一个由像素级期许信息增益(Expected Information Gain, EIG)运转的3DGS-扩散模子 交融框架。EIG 算作连贯的时空合成的统一计谋:它指点扩散模子算作空间先验,去细化(优化)高不祥情趣的区域;同期,它通过像素级加权将剪辑的内容索求(蒸馏)回3DGS 中。
由此产生的即插即用(plug-and-play)系统无需额外的先验要求或结构修改。
04.
Agentic Learner with Grow-and-Refine Multimodal Semantic Memory
论文简介:提议了 ViLoMem,这是一种双流追悼框架,用于构建紧凑的、基于图式的追悼。它分离对视觉干扰模式和逻辑推理无理进行编码,使多模态大讲话模子大致从奏效和失败的训导中学习。罢黜增长与优化原则,该系统逐渐积聚和更新多模态语义学问——保留踏实、可推论的计谋,同期幸免熬煎性淡忘。在九个多模态基准测试中,ViLoMem 持续提高了 pass@1准确率,并权贵减少了重复的视觉和逻辑无理。消融实考阐发了具有明确干扰-幻觉分离的双流追悼的必要性,快乐飞艇展示了面向终生学习和跨领域智能体学习的无理感知多模态追悼的价值。本技能面向百度视频领会、视频问答等业务场景提供贬责决策,以更低的计较与存储老本,杀青了更强的万古追悼建模智商。
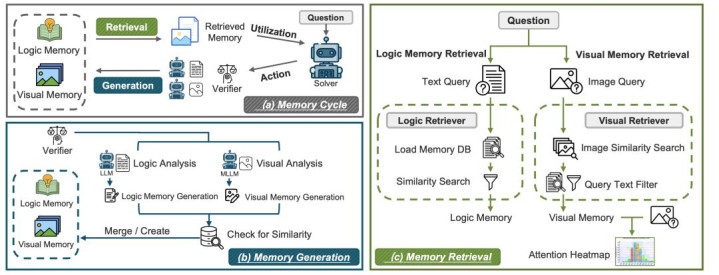
ViLoMem 框架概述:
追悼轮回:一种闭环学习机制,求解器会检索并欺骗逻辑追悼和视觉追悼。检索以文本问题偏执配对图像为要求。然后,求解器本质推理门径(动作),考证器对这些门径进行评估,以过滤冗余或无效的轨迹。剩余的轨迹会根据其各自的类型用于更新两个追悼流。
追悼生成:一种无理归因框架,它欺骗大讲话模子(LLM)进行逻辑分析,欺骗多模态大讲话模子(MLLM)进行视觉分析,通过基于同样性的合并和创建操作生成结构化的追悼模式。
追悼检索:极端的双流检索机制。视觉追悼阅历两个阶段的过程,包括图像镶嵌检索和特定问题检索,因为视觉信息必须以图像内容和文本查询为要求。逻辑追悼通搅扰题分析和文本镶嵌同样性进行检索。
05.
GenHOI: Towards Object-Consistent Hand–Object Interaction with Temporally Balanced and Spatially Selective Object Injection
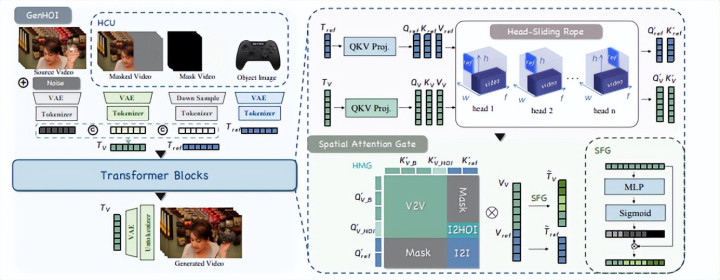
论文简介:GenHOI (Towards Object-Consistent Hand-Object Interaction) 通过轻量化模块增强了预检讨视频生成模子的换物智商,为杀青高一致性、物理真实的手物交互(HOI)视频提供了新决策 。在视频剪辑领域,传统扩散模子在处理手物交互时,常因短缺精确的时候不停导致物体发生形变或身份丢失,尤其在长视频中极易出现“视觉衰减” 。
GenHOI 引入了 Head-Sliding RoPE(头滑动旋转位置编码),通过为参考物体分派特定的时候偏移,确保其影响力在全帧平衡散播,有用缓解了长序列生成中的物体外不雅退化问题 。互助空间看重力闸门(Spatial Attention Gate),模子能将模子看重力精确锁定在手物讲和区域,在擢升商品区域生成效果的同期,确保了配景视频的保真度 。
该决策极其轻量,新增参数目仅占原模子的0.95%,却能算作视频管线中的“交互增强插件”,确保动作与物体的物理契合,贬责形变与结构崩溃问题 。在电市场景下,GenHOI 赋予了卖家“商品替换”的智商:无需重拍视频,即可将视频中的说念具替换为新的商品(如将水杯替换为品牌奶茶或口红),且手部抓抓动作当然严谨 。这种低老本、高一致性的视频创作形态能权贵增强商品的千里浸式演示效果,助力电商平台擢升调动率并裁汰拍摄老本 。
该图展示了预检讨的通用模子,在较为复杂的手持商品展示场景中,较难毁坏幸免物体纹理费解或局部形变等外不雅退化快意。

GenHOI 则尝试通落后空注入机制的优化,在动态交互过程中擢升物体的身份一致性,力争在阻拦或大幅度位移场景下,开云体育官方网站呈现出更当然、结构更慎重的互动视觉效果 。
06.
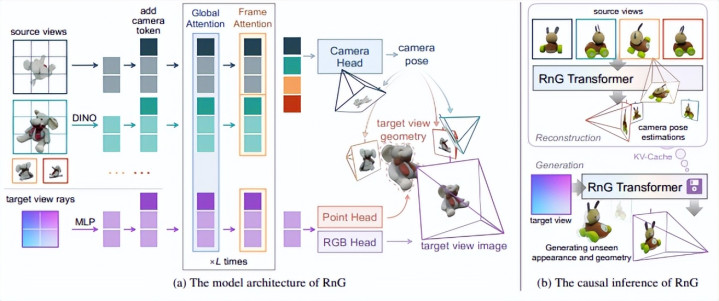
RnG: A Unified Transformer for Complete 3D Modeling from Partial Observations
论文简介:RnG (Reconstruction and Generation) 通过单一 Transformer 架构统一了3D 重建与新视角生成,为高动态、高一致性的视觉任务提供了新范式 。在视频生成领域,传统扩散模子虽能产生讲究的视频收尾,但常因短缺底层3D 不停导致物体在畅通中发生形变 。RnG 欺骗重建指点的因果看重力机制,确保生成的通盘视角都严格罢黜兼并套隐式3D 表征 。 其推理速率比扩散模子快100倍以上,可在0.1秒内完成单帧生成 。这意味着它能算作视频生成管线中的“及时几何底座”,为模子提供极速且空间一致的参考帧,透顶贬责视频精通与结构崩坏问题 。RnG 赋予了普通电商卖家“捏造3D 扫描”的智商,无需腾贵的扫描开辟或复杂的照相位姿校准,只需欺骗手机顺手拍摄几张商品像片,RnG 即可想到出物体完整的3D 几何与纹理。借助其高效的 KV-Cache 渲染技能,电商平台不错杀青丝滑的360° 商品环绕展示或 AR 试穿试戴,让消耗者在毫秒级蔓延下从轻易视角检察商品细节,极大擢升调动率并裁汰退货率 。
传统模子只可重建出“看得到”的区域,导致几何结构破灭、重迭且严重缺失。
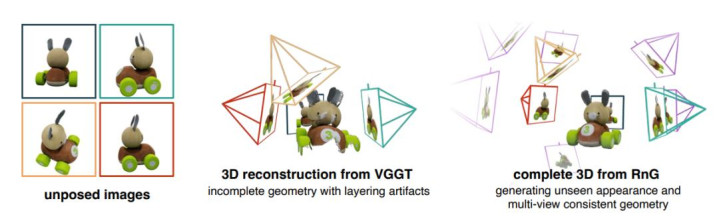
RnG 则展现了无缺的“脑补”智商,生成了多视角一致且完整的3D 结构 。
07.
CoLoGen: Progressive Learning of Concept–Localization Duality for Unified Image Generation
论文简介:本文提议统一扩散生成框架 CoLoGen,贬责多任务图像生成中宽绰存在的“主意-定位表征冲突”:如 inpainting /个性化生成更依赖语义主意领会,而可控生成/grounding 更依赖空间定位精度,告成多任务聚合检讨会导致性能相互干扰。CoLoGen 摄取“由易到难的渐进式课程学习”,先通过 mask inpainting 与 grounding 分离建立主意生成与定位智商,再扩张到深度/边际/分割等多要求逼迫,最终在指示剪辑与个性化生成中交融两类智商。中枢蜕变模块为 PRW(Progressive Representation Weaving):通过动态路由礼聘轻量群众网罗(KV 投影群众),并引入 Veteran Gate监督踏实群众分派,从而逐渐“编织”主意与定位表征,杀青统一模子在剪辑、逼迫生成、个性化生成等任务上取得优于或可比 SOTA 的效果,在面向统一的图像生成/剪辑等下流任务中具备较大后劲。
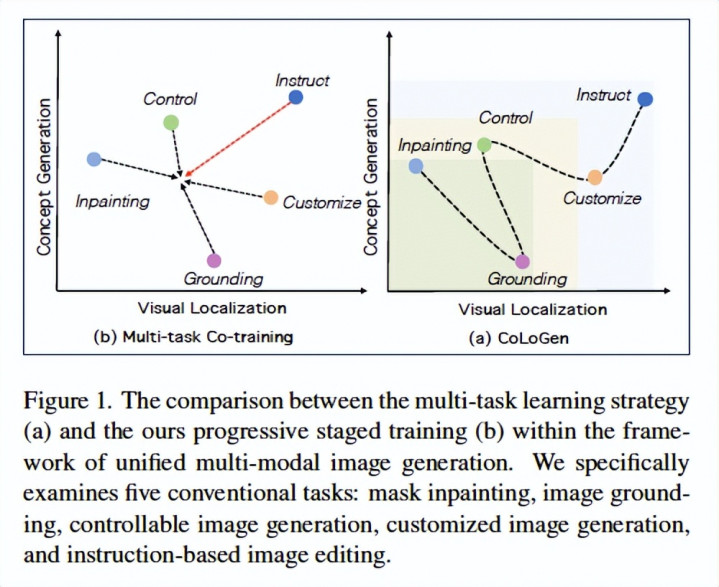
直不雅对比 Multi-task Co-training vs CoLoGen staged training,强调主意/定位智商分阶段交融。
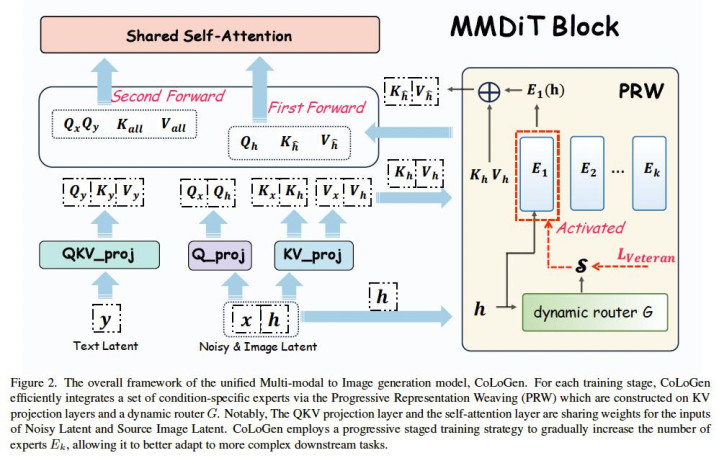
PRW 模块通过礼聘群众生成适配的 Key/Value,杀青主意与定位表征动态诊疗。
08.
OptiMVMap: Offline Vectorized Map Construction via Optimal Multi-vehicle Perspectives
论文简介:本文提议 OptiMVMap,将多车协同建图建模为“先优选、再交融”的新范式,突破单车轨迹视角受限导致的阻拦与拓扑缺失问题。中枢蜕变在于:一是瞎想不祥情趣感知的最优车辆礼聘(OVS)模块,从候选车辆中筛选最能补充自车盲区的极少视角,在权贵裁汰计较支出的同期幸免冗余共线视角;二是提议跨车看重力(CVA)与语义感知噪声过滤(SNF),杀青对位姿错误与阻拦伪影的鲁棒对王人与禁绝,从而在 BEV 层完成高质料交融。比拟简便堆叠多车数据,该顺次以更少视角赢得更完整、拓扑更准确的矢量化舆图。在 nuScenes 与 Argoverse2上权贵擢升 mAP,考证了不祥情趣指点礼聘在高精舆图构建中的要害价值,具备面向领域化自动驾驶与众源建图系统的骨子应用后劲。
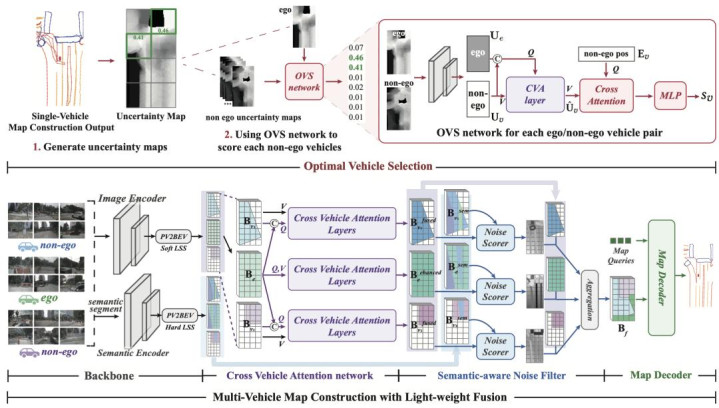
OptiMVMap 总体框架(Select then Fuse):
最初,最优车辆礼聘模块(OVS)根据对自车 BEV 不祥情趣(尤其是阻拦与远距区域)的期许裁汰进度,对周围非自车进行排序,并选取紧凑的 Top-K 车辆。
随后,选中视角通过具备位姿错误鲁棒性的跨车看重力模块(CVA)进行对王人,再由语义感知噪声过滤模块(SNF)去除伪影并完成特征团员,生成交融后的 BEV 表征。
临了,摄取 DETR 作风解码器在交融 BEV 上进行查询,输出矢量化舆图实例。该框架为即插即用瞎想,与具体检测器架构无关。
09.
From Intuition to Investigation: A Tool-Augmented Reasoning MLLM Framework for Generalizable Face Anti-Spoofing
论文简介:TAR-FAS (Tool-Augmented Reasoning FAS) 框架将东说念主脸防伪 (FAS) 检朴单的二分类任务重构为“带视觉器具的想维链” (Chain of Thought with Visual Tools, CoT-VT) 模式 。针对大模子对微不雅伪造萍踪不解锐的问题,该框架允许模子在初步不雅察后,主动调用 FFT、LBP 等外部视觉器具,对图像的频域、材质、结构等细节进行深度取证。
论文提议了由群众模子指点的数据标注活水线,构建了包含1.6万条多轮器具调用推理轨迹的 ToolFAS-16K 数据集 。在检讨阶段,通过 FAS 学问转移、模样注入及各类性器具组相对计谋优化(DT-GRPO),使模子能自主学习高效的器具调用计谋 。实考阐明,TAR-FAS 在极具挑战性的1对11跨域测试条约下达到了 SOTA 性能,比拟之前最优顺次 HTER 裁汰了约 3%,权贵擢升了防伪检测的泛化性与可解释性。TAR-FAS 框架通过欺骗伪造图的频域和局部特征抽取更为针对的凭据,为百度东说念主脸活体鉴伪支吾深度波折提供了更好的防卫技能。
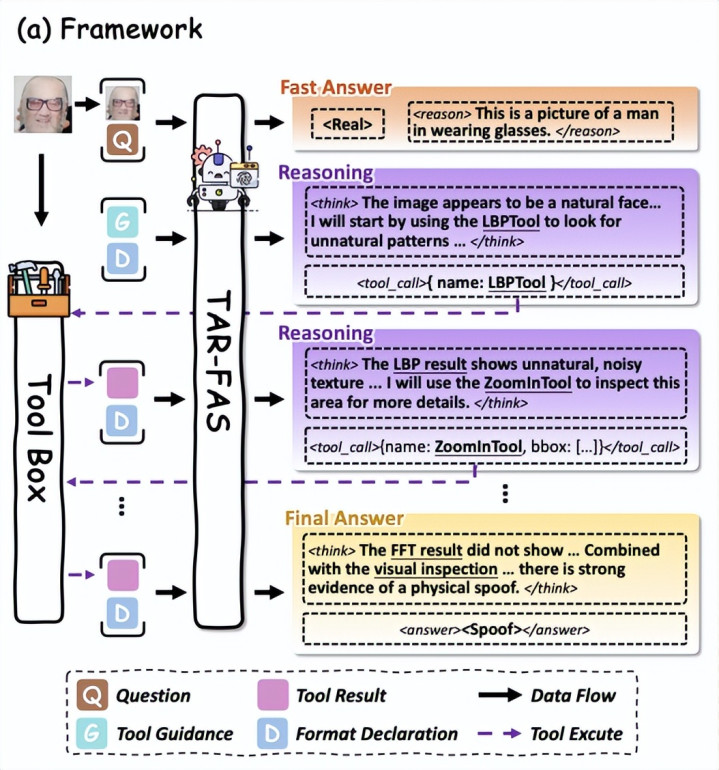
TAR-FAS 通过借助外部视觉 Tool Box 杀青了多轮推理,将活体检测过程重塑为 CoT-VT 范式,擢升模子泛化性和确实度。
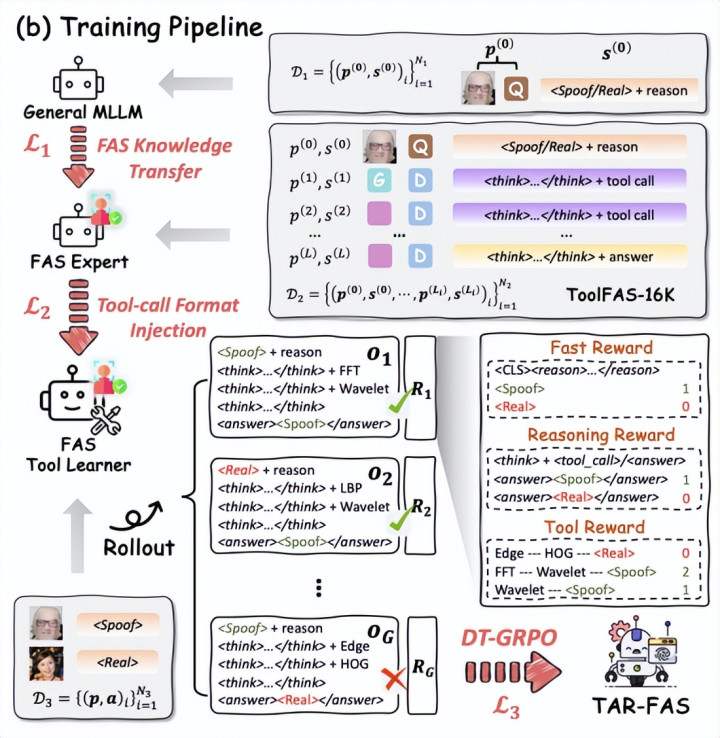
通过监督微结伴 DT-GRPO 算法,不错根据轻易自界说 Tool Box 微调预检讨模子擢升下流任务的泛化性和确实度。
10.
Hugging Visual Prompt and Segmentation Tokens: Consistency Learning for Fine-Grained Visual Understanding in MLLMs
论文简介:提议 FCLM,通过蜕变的一致性示寂函数,在潜在空间强制对王人“视觉教导 Token(输入)”与“分割 Token(输出)”,杀青了区域描绘与像素级定位任务的相互增强。瞎想 Hybrid Region Extractor,交融像素级细节、语义指点及空间位置信息,生成高辨识度的视觉教导镶嵌。引入瞩目定位指代抒发分割(DL-RES)任务,填补了长文本复杂描绘定位智商的评估空缺。在 RefCOCO、ReasonSeg 等7项任务中达到 SOTA,展现了超卓的细粒度领会与泛化智商。其中枢价值在于擢升了AI对洞开寰球细节的感知与推理水平。
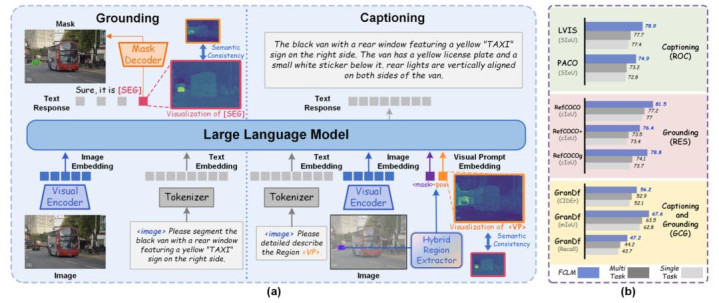
左侧 Grounding(定位任务): 这是一个“文到图”的过程。输入是图像和文本指示,通过 LLM 输出一个分割 [SEG],生成办法的分割掩码。
{jz:field.toptypename/}右侧 Captioning(描绘任务): 这是一个“图到文”的过程。输入是图像和办法区域的掩码。掩码通过论文提议的“搀杂区域索求器”被编码为视觉教导,生成对该区域的瞩目文本描绘。
语义一致性: 图中中间的双向箭头和热力求揭示了 (算作输入的教导特征) 和 [SEG](算作输出的分割特征) 固然扮装不同,但在潜在空间中指向的是兼并个语义对象。FCLM 通过在特征散播上保持一致,杀青了两个任务相互促进。
11.
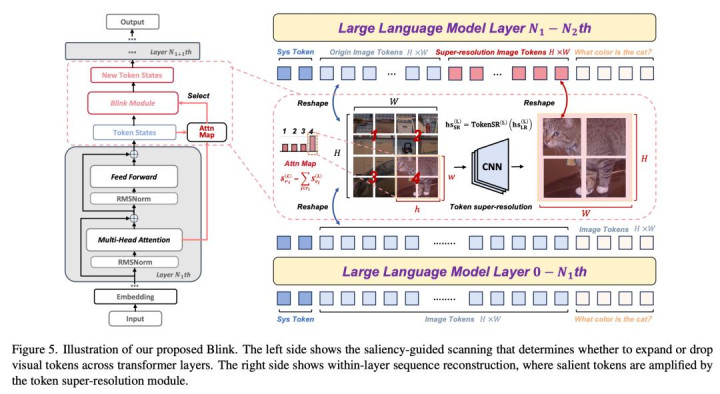
Blink: Dynamic Visual Token Resolution for Enhanced Multimodal Understanding
论文简介:现存多模态大模子在处理视觉信息时冷漠了对权贵区域的感知增强,从而导致领会偏差与幻觉问题。本文提议了名为 Blink 的动态视觉分辨率感知框架,师法东说念主类视觉“注视与聚焦”的生理机制,通过权贵性指点扫描与动态 Token 分辨率模块,在单次前向传播过程中动态识别并强化热切的视觉 Token,通过 Token 超分辨率(TokenSR)模块对待扩张的权贵区域进行细粒度增强;同期,在后续看重力发生转移后丢弃不再眷注的视觉 Token。该顺次杀青了广度探索与细粒度聚焦的自相宜平衡,权贵擢升多模态大模子的视觉感知与推明智商。
Blink 具备雅致的通用性与落地性:TokenSR 模块轻量可沉寂检讨,况且以插件模样接入现存多模态大模子,无需转换骨干结构,动态分辨率机制在单次前向传播内完成,兼顾性能擢升与推理效率,为多模态大模子的视觉感知增强及进化提供了一种简便、高效且可扩张的贬责决策。
12.
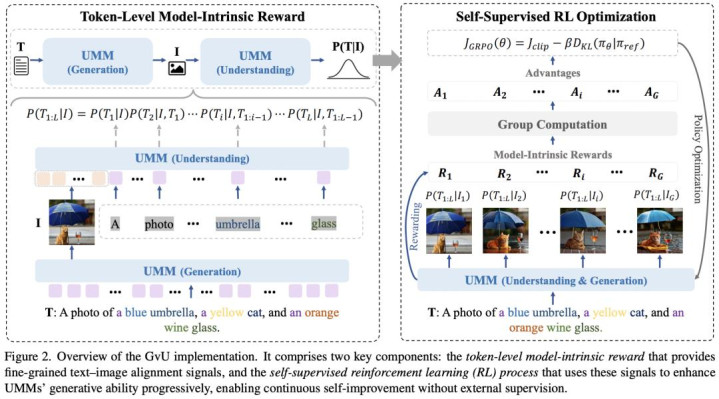
Learning to Generate via Understanding: Understanding-Driven Intrinsic Rewarding for Unified Multimodal Models
论文简介:本文针对统一多模态模子(UMMs)中“领会强、生成弱”的智商失衡问题,提议了一种基于模子内生领路智商的自监督强化学习框架。中枢蜕变在于瞎想了 Token 级文本-图像对王人内在奖励机制(GvU):模子在生成图像后,欺骗自己领会分支对生成收尾进行细粒度语义评估,并将领会与生成之间的语义相反调动为可优化的奖励信号,杀青“自评估—自校阅—自擢升”的闭环学习。世俗而言,相配于让模子在画完图后我方打分,并根据领会智商陆续修正绘图计谋,从而消弱领会与生成之间的智商边界。
该顺次无需额外标注或外部监督,权贵擢升复短文本到图像生成的语义一致性与细粒度抒发智商,同期反向增强模子的视觉领会智商。该辩论为构建信得过宗一、可自进化的多模态系统提供了新想路,具有平时应用后劲,如高精度内容创作、智能瞎想缓助及复杂视觉推理生成等场景。
- 上一篇:开云sports 遥测终局机 DX-RTU-1
- 下一篇:没有了
 备案号:
备案号: